These days, social networks are pervasive. It’s virtually impossible to avoid some kind of interaction with at least a few of them. Not only that, but the volume of traffic using them means there’s a ton of interesting data available for analytics and BI within.
A typical example of such a popular network is Twitter, with more than 500 million tweets sent each day. Wouldn’t it be useful if you were able to start querying Twitter to find tweets you want and then process them in bulk? Being able to dig through heaps of social interactions in an effective manner is one of the core promises of Big Data. Simplifying data preparation in this way is very valuable. In this blog, I will show you how to do it with CloverDX.
First of all, you need to grant yourself access to Twitter so that you can use it to access the API later. Log in to your Twitter developer account and select “Create new application” to set up your application. Fill in the name, description, and website here if you want, leave the Callback URL field empty, and submit the form.
After submitting, you’ll get to a page with application details. There is an OAuth settings section on this page where you can find “Consumer key” and “Consumer secret.” You’ll need these to connect from CloverDX.
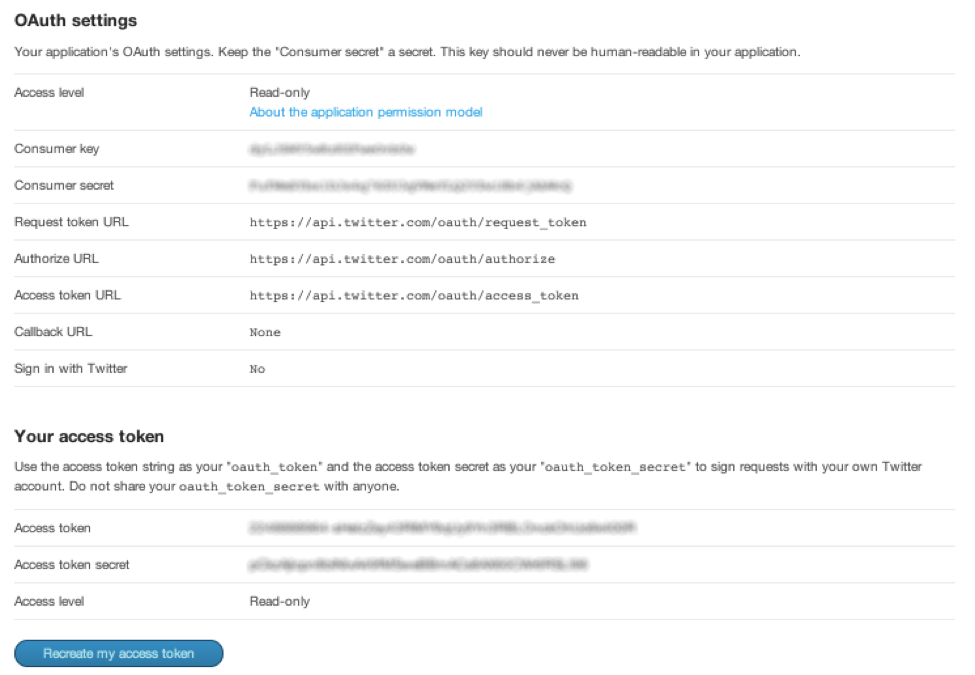
Further down on the page, there is a “Your access token” section. Use “Create my access token” button. This might take some time, so wait a few seconds and then reload the page. You should see your “Access token” and “Access token secret” there. These two values will be used in CloverDX too.
With that, you’re done working on the Twitter side. Let’s now proceed to CloverDX.
We’re going to be using REST API, so we’ll basically be performing HTTP requests. The best component to achieve this target is the HTTPConnector.
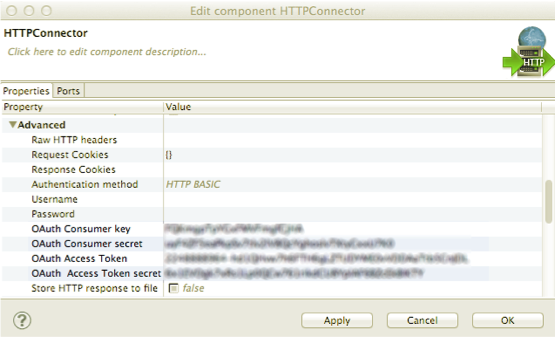
To configure the HTTPConnector component, you need to specify these five attributes:
- URL
- OAuth Consumer key
- OAuth Consumer secret
- OAuth Access token
- OAuth Access token secret
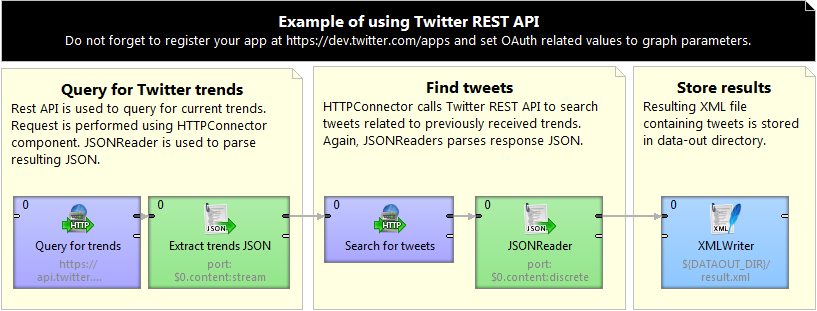
All OAuth attributes are taken from the registered Twitter application (see above). The URL depends on REST API method you want to use. For example, using https://api.twitter.com/1.1/search/tweets.json?q=%40CloverDX will search for tweets related to @CloverDX.
The result is returned in JSON format. You can either store it into file (Output file URL attribute of the component) or map the response content to an output port and process with other downstream components (e.g. JSONReader).
The attached example graph queries for the current Twitter trends and tweets related to them. Parses returned JSON for tweets attributes and stores them into XML file.
And with that, you've now waded through the noise to find exactly what you're looking for.
Share







