In short—no. Files will stay with us despite all the modern approaches we see today, like web services or data streaming.
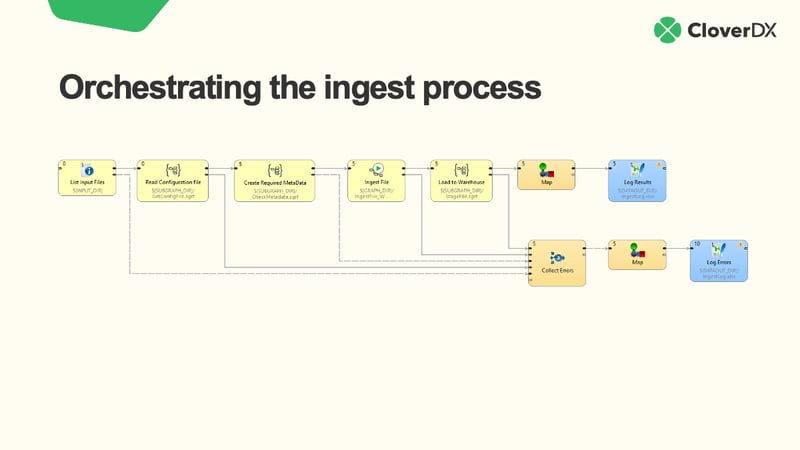
Files have been used for exchanging data amongst applications for decades. File based automation simply means one application produces a file (think of a CSV or Excel export or some scheduled data dump) and then the file embarks on a journey through some transport like an FTP upload, shared folder or email. On the receiving end, another application picks the file up and processes it.
Although the workflows can get much more complex, the core beauty of files lies in their simplicity, their extremely vast support ranging from embedded systems to archaic mainframes and lastly, transparency. Yes, I believe the very fact that you can “see” files makes them so popular. You can touch a file on your drive by viewing it’s raw content to sense check what you’re dealing with, virtually no tools required. Compare that to “touching” a message that just went through an API, you need specialized tools and the message is gone now anyways. There is also a bit of a story behind each file. At some point they get created, modified, you can copy and move files around, you can send files in emails, etc.

This simplicity makes files resilient against modern yet more complex mechanisms. Yes, Web Services often are a much better option if you want to exchange data on-demand, without the hassle of managing files and temp spaces somewhere. Or, data streaming definitely works better for real-time and high data volumes that need to be processed instantly. But I bet you none of these are going to completely replace files in the foreseeable future. The inherent persistence and accessibility of files, no need for specialized tools to get to the data in them, and the possibility of manual intervention if there’s a problem, is a strong “selling point” for files even today.
Just like email - did you know email predates the World Wide Web? - survived all the new communication tools like Facebook, Slack or Skype, files follow the same history. They’re just too simple to go away. People are so used to files, emailing spreadsheets, uploading data over FTP, importing and exporting CSVs, that they like to translate the same patterns into processes that are designed primarily for machines.
Everything you need to know to choose the right solution for your business in The Buyers' Guide to Data Integration SoftwareFile Automation Killer
Our dev team have recently been working on a new major new feature called Data Services, which was introduced in CloverDX version 4.7 (read more in the release notes for CloverDX 4.7). To no surprise, it’s one of those modern “file exchange killers”. Simply put, with Data Services you’ll be able to take a transformation, publish it as an API endpoint on CloverDX Server and hook its inputs and outputs to the API call. Then, applications can exchange data via this web service with CloverDX directly—fresh, transformed on-demand back and forth, no intermediate files, no temp space management, no FTP uploads.
It got me thinking—while this sounds great, my experience tells me organizations won’t be that quick in adopting this approach. When I spoke to Pavel Najvar, Head of CloverDX Product Marketing, he confirmed the vision behind Data Services lies elsewhere.
“We’re not trying to replace one thing with another. CloverDX is about interoperability. With Data Services we’re simply expanding your options. In reality, it’s quite possible that CloverDX will be orchestrating file exchange with one application on one hand, and make the same data consequently available to another application via this Data Services API on another. We can never know what environments our customers work in and our goal is not to enforce any standards. Instead, we build CloverDX to fit anywhere without too much of an “environmental impact”.
I see that when I talk to existing customers and people trialling our software for the first time. Only a few have the luxury to build their systems up every two years from the ground up with the best modern technology. In reality, mature businesses are always in some sort of a never ending transition, constantly innovating here and there. Moving bits of the technological landscape of an organization always means you get some legacy systems, which are too old and cumbersome to integrate with others and some that are so new that, well... they’re cumbersome to integrate too. “That’s our job, be the platform that makes bridging data between any two systems in your organization possible, and automate that process along the way,” explains Pavel over now empty coffee in our kitchen room.
File based automation is going to stay with us for a while. There are just too many organizations that would send you an email with an Excel attached every Monday, and you’ll always need some way of ingesting that data automatically. The modern options make a lot of sense as you gradually move your business forward and rethink how you operate. A couple of years ago, it was acceptable to look at yesterday’s data. Today, data from an hour ago is fine, and many organizations are rethinking their data pipelines to get direct access to present data with the lowest latency possible.
And who knows, maybe one Monday you won’t receive that Excel report any more and there will be an API instead. You can bet though, it’s not going to be this Monday.
To learn more about Data Services in CloverDX, and how it enables you to publish data and transformations on demand, watch the 2 minute introduction video.
Guide: The 13 Stages of a Data Migration Project and How to Manage Them SuccessfullyShare